Getting the record straight
One of the frustrations of doing road-transport energy audits is the inadequacy of the data that vehicle operators record. Unless they can download consumption and distance data from the vehicle itself, they are unlikely to have much more than fuel-purchase data complemented by unusable mileage readings (the term ‘mileage’ here includes odometer readings in kilometres).
Unusable mileage figures are a major problem. For example, fuel bought on fuel cards should be accompanied by mileage records, but everyone knows that these are usually missing or incorrect. Some organisations make efforts to collect the right data but fall short: among my recent clients Company ‘S’ for example had a rigorous process for recording the daily start and finish mileages for their HGVs, along with fuel purchased during the shift, but that left huge uncertainty because a vehicle could have been refuelled at any point in a shift which could have covered hundreds of miles. And even if the mileage had been recorded at each refuelling, the driver would need to consistently brim the tank on each occasion to make the record accurate. As a result, their MPG reports were wildly erratic. In Figure 1 I compare a typical vehicle from Company S’s fleet (left) with one from Company H which collects data from its vehicles’ onboard systems:
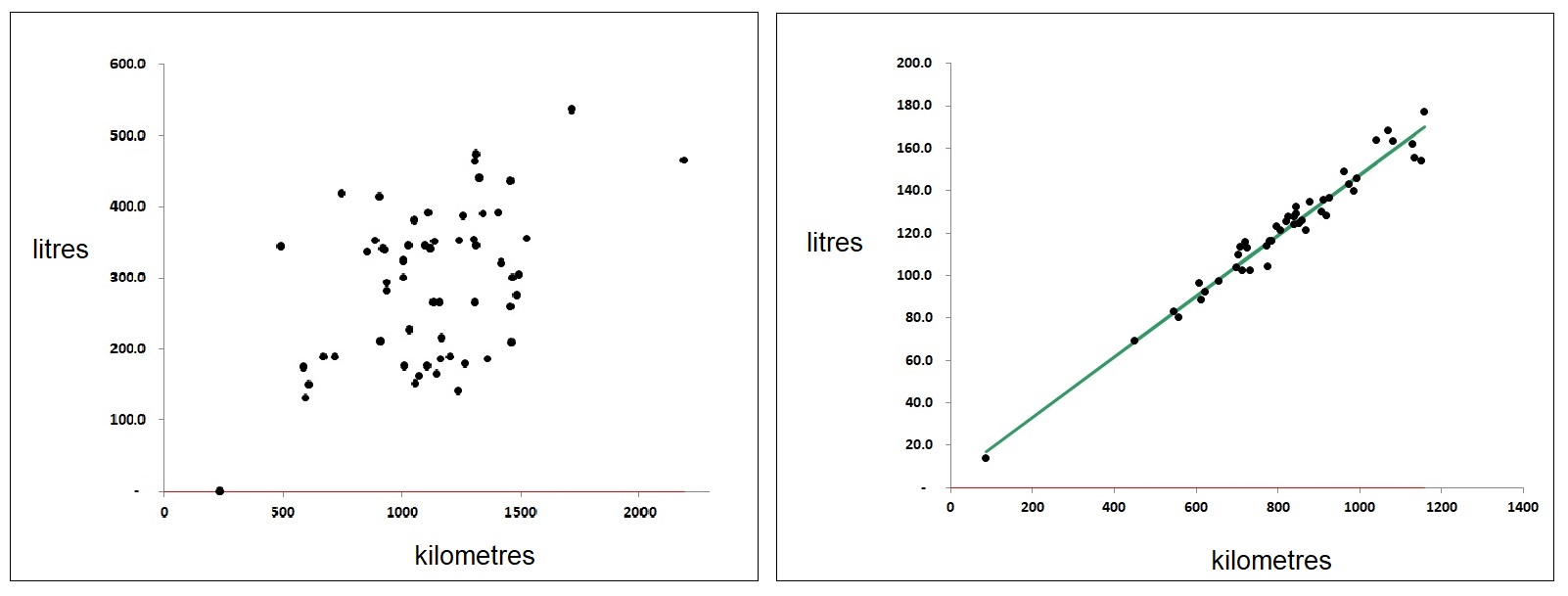
Company S (on the left) can probably get a reasonable estimate of annual MPG for each vehicle but not much more. Company H, on the other hand, can detect deviations from expected fuel economy on a weekly basis and intervene promptly wherever it has deviated significantly. For sustained deviations they can also discern the nature of the change and discriminate between fixed and mileage-related excess consumption.
For vehicles where telemetry data are not available, the user needs to adopt a recording protocol that will yield accurate consumption and distance data at regular intervals. Of course this is not as straighforward as it might be for metered consumptions, because you cannot get a fuel ‘reading’ at the end of each period (week or month). The trick I have settled on is this: the data points for each period consist of (a) the sum of all fuel taken during the period and (b) the mileage between the last fill of the period and the last fill of the previous period.
Figure 2 illustrates a spreadsheet in which this is method is used for a monthly review.
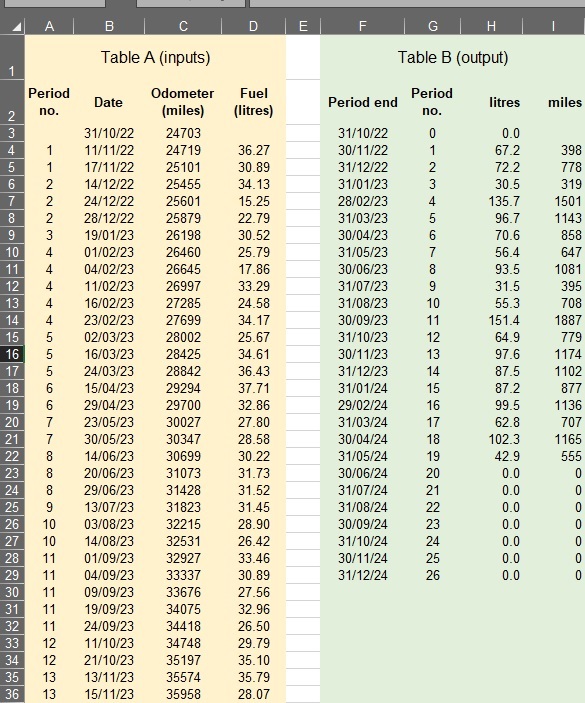
Note it is crucially important that drivers consistently fill their tanks to the brim. Actual refuelling data go in Table A, columns B, C and D, while the regularised monthly litres and mileage are calculated in Table B. What links the tables is a column of ‘Period numbers’. They are defined in Column G as simply the sequential row number of the table, and in column A they are calculated by looking up the Table A date in column B. Thus by way of an example the Table-A entries for 03/08/23 and 14/08/23 belong to period 10 .
Meanwhile in Table B…
- the logic for calculating the incremental distance just looks up, in Table A, the finish mileages for the current and previous periods based on the period-end dates (and takes the difference); while
- the litres value uses a SUMIF() function to summate all the values in Column D that have the matching period-number in Column A.
There is a copy of the example worksheet here for anyone who wants it as a starting point for their own projects. It can be made to work on a weekly cycle simply by setting the period ends in Column F at seven-day intervals.
Finally Figure 3 shows analysis of monthly fuel consumption for the passenger car whose data appeared in the example above:
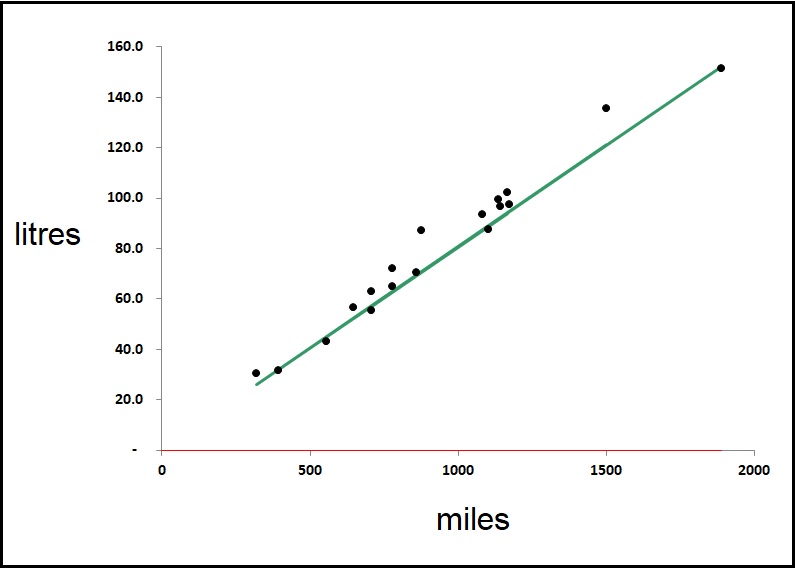
Despite the random refuelling pattern, the correlation is reasonable and in fact would have been better were it not for the fact that performance was worse prior to July 2023 and from January to April 2024.